
OpenOrb - a curated RSS and Atom feed search engine
Two weeks ago, I built a search engine which only searches over a list of RSS feeds you expressedly give it. If you regularly read ten blogs, you can add those ten to the engine, and then search for stuff in them. I called it OpenOrb - if you click on that link, you'll be able to use my own instance. RSS feed readers can usually do this sort of thing, but RSS readers aren't meant to be shared, so you can think of the search engine as a 'curated feed list as a public service'. I'd love to see people setting up their own OpenOrb instances to allow public access to the lists of blogs and writers they've carefully spent years curating.
I named OpenOrb after the 'pondering my orb' meme, which was originally an illustration by Angus McBride for a 1988 gamebook (a single-player pen-and-paper roleplaying story contained in a single book) called A Spy in Isengard.

Niche, purposefully small-scale, and custom search engines have been turning up in my HackerNews and Mastodon feeds a lot recently. In part, this is a bubble effect - I'm interested in the handmade web and IndieWeb, in self-hosting, and in alternatives to the enshittification of dominant web platforms. When I was getting rid of my Facebook account in 2018-19, I built a small-scale, communally governed social network, Sweet, which is no longer running, and a federated event sharing service, Gathio, which very much is. So I'm exactly the sort of audience to appreciate an alternative search engine.
Google sucks now
Of course, there's another reason why alternative search engines are becoming more popular - it's because Google sucks now. The research paper which that Register article references notes that Google, Bing, and DuckDuckGo - which primarily uses Bing for its search results - all appear to be losing the game against content farms, which exploit the behaviour of search engine algorithms designed to integrate with the SEO economy, flooding search result pages with shitty, machine-generated content. In response, search engine operators have two strategies: (1) constantly screen and adjust search results by removing machine-generated drivel, which costs a lot of money; or (2) take more control of their search results at source - making them less organic, showing more ads, and platforming only the companies who pay them, which makes a lot of money. Whichever strategy Google is leaning into, it's now an adage of sorts that the only way to reliably find a human-generated product review or recommendation on Google these days is by typing in whatever your search term is and adding 'reddit' at the end. Google knows this very well, which is why it's signed a $60 million dollar deal with Reddit to license its user-generated content:
Over the years, we’ve seen that people increasingly use Google to search for helpful content on Reddit to find product recommendations, travel advice and much more. [...] This partnership will facilitate more content-forward displays of Reddit information [...].
The enshittification ouroboros
It's easy to point the finger of blame at the evil, unscrupulous AI herders who have come down from the mountains to graze their flocks of awful, noisy, shitty goats in the pristine meadows of our search pages. It was, of course, Microsoft and Google who gave them the goats in the first place - and created the situation where in the modern Internet economy, if you want to make any money at all, you have to find a way to get your goats into the meadow, any way you can.
But the death knell for the Internet as we knew it wasn't sounded last year, or even in the early 2010s, when content farms - then human-written - became a serious issue. It sounded when the great tech powers decided that access to information was a monetisable concern. As Doctorow writes in the enshittification piece I linked above:
Searching Amazon doesn't produce a list of the products that most closely match your search, it brings up a list of products whose sellers have paid the most to be at the top of that search.
The same goes for Google and Bing. The scale doesn't really matter - it's just particularly appalling when it happens on the titanic level of search engine indexes. On the smallest scale, if I ran a zine distro where people gave me their zines to sell, and I would sell those zines for cost, perhaps with a markup to keep my distro running, every visitor would have the same experience. But if I gave preferential treatment to people who paid me to sell their zine, I'd end up with tables of awful, garbage pamphlets made by people with too much money, and visitors who cared about quality zines would suffer. If I gave even more preferential treatment to producers who spruiked my own zine distro in the pages of their zines, I'd end up with the Google search results page for 'best backpack' in April 2024 - a grim, sad, deeply useless ouroboros constantly shitting its own words back into its mouth.
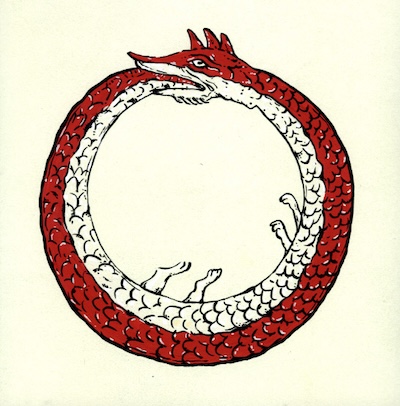 Everyday In 2024 11 Guide 2024 Backpacks Use To Men Backpacks Best Laptop Of Backpacks 12 Buy in 2024 For For 25 Backpacks The Best Buyer's 2024 Best Best Travel
Everyday In 2024 11 Guide 2024 Backpacks Use To Men Backpacks Best Laptop Of Backpacks 12 Buy in 2024 For For 25 Backpacks The Best Buyer's 2024 Best Best Travel
A comment on a TikTok I saw recently almost hit the nail on the head: "The problem with the Internet is that it always thinks you're shopping, even when you're not". We need to go two steps further: the problem is not with the Internet, it's with the great tech powers which control the flow of easily accessible information on the Internet - Google, Microsoft, Amazon, and Meta. And they don't always think you're shopping. They're desperate for you to always be shopping.
The alternatives
Google's winning formula is scale - that, and it's been around so long that the Internet has been built around its algorithms. Altrernative search engines need to find other niches to work well, and there are plenty. Blogger Seirdy has written a fantastic and comprehensive list of search engines, including some really specific ones. Some of my favourites are:
- Stract - open source, "made for hackers and tinkerers", with optional 'optics' written in a simple DSL used to tune search results. For instance, I can search for content only on the Fediverse; only on the IndieWeb and blogs; or only in developer documentation sites.
- Marginalia - a precious, lovely search engine which focuses on text-only, non-commercial sites. "Where this search engine really shines is finding small, old and obscure websites about some given topic, perhaps old video games, a mystery, theology, the occult, knitting, computer science, or art."
- Teclis - takes a similar approach to Marginalia, and is built by the creator of Kagi, which is a paid-for, ad-free generalist search engine. It combines its indexer with an ad-blocker: if the ad-blocker notices more than 5 ads on the site, it doesn't get indexed.
OpenOrb
It's been a roundabout journey, but we're back at OpenOrb. I mentioned ideas about alternative search engines appearing on my Mastodon feed. I was originally inspired to create OpenOrb by this post by @vesto:
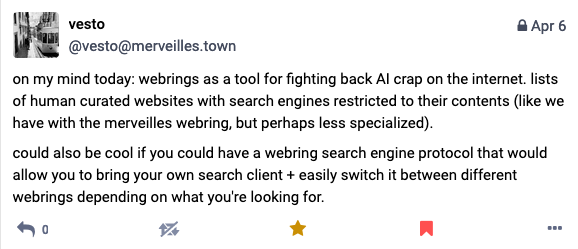
That's precisely what I want OpenOrb to be - a list of human curated websites with search engines restricted to their contents. Gone is the awful, shitty ouroboros of the late capitalist hellweb. Back is the joy of curation, discovery, collection, and categorization which made the early web so delightful, at least in my memory. Who needs Google? If I need a new backpack, I'll ask my friends who have backpacks. If I want to remember which blogger I follow wrote a really excellent guide to setting up the Linux window manager river, I'll use OpenOrb. Fun fact: Google searching 'river window manager setup guide' doesn't even bring up Leon's excellent post.
The current incarnation of OpenOrb works well enough for two day's worth of code, but I've got some future plans for it already:
Better indexing
Currenty, OpenOrb crawls an Atom or RSS feed. The implementation of these feeds is very loose in the wild - some feeds contain a site's entire content, while others will only have the last ten posts. Some will contain full text content for a post, while others will contain only a short excerpt, or nothing. Some will have a reliable 'last updated' date, some will not, or the date will be configured wrong. The way OpenOrb works now, it will index all the content from an RSS feed it's given. If a feed entry doesn't have any content, it will go to the original post that entry links to, and try to read the content from there. But as @vesto suggested on Mastodon, there's another option: properly crawl the content of all the sites imported into OpenOrb (while respecting robots.txt, of course), so that all content, even content not in the RSS feed, will be indexed. This is the dream.
An API
An OpenOrb instance should have a machine-accessible API. This isn't hard to do at all.
Federation
It would be lovely if my personal instance could 'follow' other instances I really like. If someone else has a great collection of D&D and tabletop roleplaying blogs which they're indexing via OpenOrb, but I don't want to import them directly into my OpenOrb, I should be able to connect my instance to theirs. Then, someone searching on my instance could choose to only search over local content, or include content from federated peers.
Better search
At the moment, the actual search engine part of OpenOrb almost wholesale borrows its code from Alex Molas's search engine in 80 lines of Python. This search engine is surprisingly robust! But it doesn't handle more advanced search query features like wildcards, phrases, and lemmatization/stemming (which allows a search engine to perhaps include hits for 'computer' and 'compute' when you search for 'computers' and 'learn' and 'learner' when you search for 'learning'). Over small sets of posts, I don't think these features are necessary, but it would certainly be nice to have them.
If you set up your own OpenOrb instance, I'd love to hear about it. Also, tell me about the alternative search engines you love to use, or - looking further - your favourite alternatives to search engines in general. How do you find information, discover wonderful things, and create meaningful communities and connections in the post-shitty Internet?